
Conversational Interaction Recognition
We use both 3D pose and face features to learn and recognize different conversational interactions. In this work, we utilise the Kinect sensor to extract 3D pose features and a combined local and global model to extract face features from normal RGB cameras. We demonstrate that both features can still be applied to effectively train classifiers, although they are contaminated with noises. The differences in interaction among different scenarios in our data set are extremely subtle. We investigate both generative and discriminative methods, and employ a subject-specific supervised learning approach to categorise the testing sequences into seven different conversational scenarios.
Data acquisition
Pose data are collected using Kinect at 30fps, while face data are captured using two high-definition cameras at 25fps. Seven tasks have been designed, including describing work, story telling, problem solving, debate, discussion, subjective question, and jokes. A total of 8-hour Kinect sequences and equal length of face sequences have been acquired (http://csvision.swan.ac.uk/converse.html).
Proposed method
We first extract motion features from Kinect output and localize facial fiducial points in RGB face images using a two level shape model. The head orientation is then computed based on face localization and is treated as part of the pose feature. The localization of face fiducial points provides two sets of features: shape and appearance. The shape features are derived from the coefficients of a global shape model that is used for face localization, while the appearance features are obtained from the textural coefficients of two local face models after linear discriminant analysis (LDA). Hidden Markov models (HMMs) are then applied to model the conversational interactions based on these low level features at individual time instances. Interactions between pair of subjects are captured using coupled HMM. A temporal generalization of both pose and face features are carried out to encapsulate temporal dynamics as well, which produces a visual vocabulary features and then further generalizes them to visual topics through latent Dirichlet allocation analysis.The interactions are classified into seven different scenarios employing the discriminative classifiers, support vector machine (SVM), and random forests (RF). Moreover, we apply modulator functions to those mid level features so that we can learn the importance of those individual features, which is then used in the SVM classification.
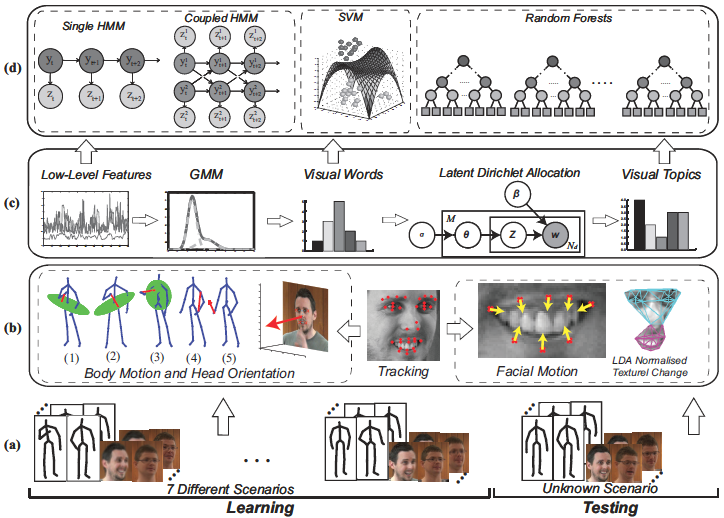 |
| Flowchart of the proposed method. |
Experimental results
The combination of pose and face features indicates remarkable improvements over using face or pose features only. With visual words, RF is inferior to others, and SVM performs better. With further generalized features, there are clear improvements for both RF and SVM, where RF is slightly better than SVM. Most importantly, with SVM ranked (SVM-R) features, we achieve substantial improvements for all the seven scenarios and improve the overall performance close to 90%. Therefore, it is clear that feature selection is important in distinguishing different conversation scenarios.
| Classi cation results using visual words (%). |
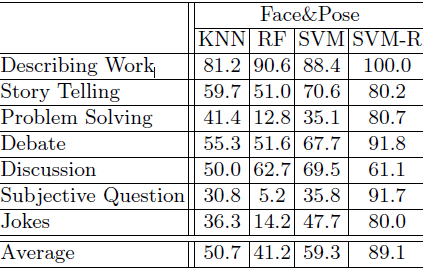 |
| Classi cation results using visual topics (%). |
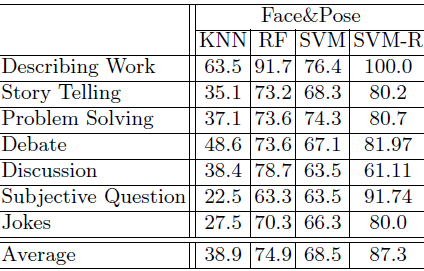 |
Publications
- J. Deng, X. Xie, and S. Zhou, Conversational Interaction Recognition based on Bodily and Facial Movement, In Proceedings of International Conference on Image Analysis and Recognition (ICIAR), October 2014.
- J. Deng, X. Xie, and B. Daubney, A bag of words approach to subject specific 3D human pose interaction classification with random decision forests, Graphical Models, Volume 76, Issue 3, Pages 162–171, May 2014.
- J. Deng, X. Xie, B. Daubney, H. Fang, and P. W. Grant, Recognizing Conversational Interaction based on 3D Human Pose, In Proceedings of Advanced Concepts for Intelligent Vision Systems, pages 138-149, October 2013.